Imagine you have a bag with 10 coins in it. Of these coins, 9 are fair and 1 is biased with {P(\text{H}) = 0.9}. The biased coin is painted red.
You pull a coin from the bag, look at it, and flip it three times. You record the sequence and whether it was the biased coin or a fair coin. You then put the coin back in the bag. You repeat this thousands of times until you have an estimate of the probability of every sequence, both for the biased coin and for a fair coin.
You now pass the bag to a friend and close your eyes. Your friend draws a coin, flips it three times, and tells you all three flips came up \text{H}. What’s the probability that your friend flipped the biased coin?
Analyzing the Experiment
Based on your many coin flips, you can analyze the possible outcomes of this experiment.
An outcome is a possible result of an experiment or trial. Each possible outcome of a particular experiment is unique, and different outcomes are mutually exclusive (only one outcome will occur on each trial of the experiment). All of the possible outcomes of an experiment form the elements of a sample space.
An event is a set of outcomes. Since individual outcomes may be of little practical interest, or because there may be prohibitively (even infinitely) many of them, outcomes are grouped into sets of outcomes that satisfy some condition, which are called “events.” A single outcome can be a part of many different events.
The sample space of an experiment or random trial is the set of all possible outcomes or results of that experiment.
Sample Space for Coin Flips: The sample space for three coin flips is
S = \{\text{H},\text{T}\}^3 = \{\text{HHH}, \text{HHT}, \text{HTH}, \text{THH}, \text{HTT}, \text{THT}, \text{TTH}, \text{TTT} \}
This set lists every possible sequence of heads (\text{H}) and tails (\text{T}) from three flips.
Sample Space for Coin Selection: The sample space of drawing a coin from the bag is
C = \{\text{fair}, \text{biased}\}
Overall Sample Space: The sample space of the entire experiment (drawing a coin and flipping it) is the Cartesian product of these sample spaces:
\Omega = \mathcal{C} \times \mathcal{S} = \{(c, s) : c \in \mathcal{C}, s \in \mathcal{S} \}
This means each outcome in the experiment is a pair: (type of coin, sequence of flips).
Visualizing with Sets
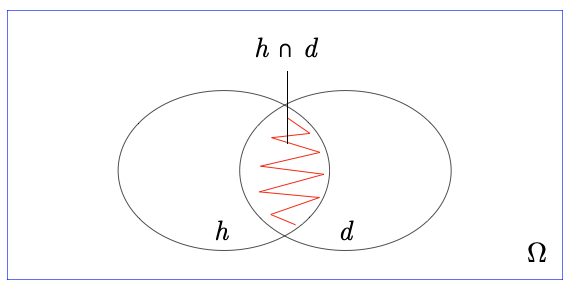
We can think of the sample space\Omega as the set of all possible outcomes in the experiment. Each point in the sample space corresponds to a unique outcome. We can draw a circle around all of the points that are described by an event, for instance that all three flips came up \text{H}. This set of points is the data (d). In this example, we condition on the event that all three flips were HEADS—meaning we restrict our attention to those outcomes. That event comprises all the outcomes (a sequence of three coin flips) where all three flips came up HEADS.
We can draw another circle around all of the points that correspond to sequences produced by the biased coin. We’ll call this set our hypothesis (h) that the coin your friend flipped was biased.
What we want to know is {P(h \mid d)}, i.e., {P(\text{biased} \mid 3~\text{H})}. This is the probability that the coin is biased given that we observed three HEADS.
Deriving Bayes’ Rule
The intersection of h and d represents all the outcomes where the biased coin was flipped and all three flips came up HEADS. We can write this probability as {P(h \cap d)}, or equivalently, P(h, d).
To find {P(h \mid d)}, we want the proportion of d’s probability that overlaps with h. This is the ratio of the probability of the intersection {h \cap d} to the total probability of d:
P(h \mid d) = \frac{P(h, d)}{P(d)}
This is the definition of conditional probability. It holds whenever {P(d) > 0}.
Algebraic rearrangement yields
P(h, d) = P(d) \, P(h \mid d)
This is the chain rule. It says that we can calculate the probability of the intersection by multiplying the total probability of d by the proportion of d that overlaps with h.
It is intuitive to understand why this symmetry exists: P(a,b) is just the probability of the intersection of a and b. {a \cap b} is the same as {b \cap a}, so
Substitution of {P(h, d)} with {P(h) \; P(d \mid h)} yields
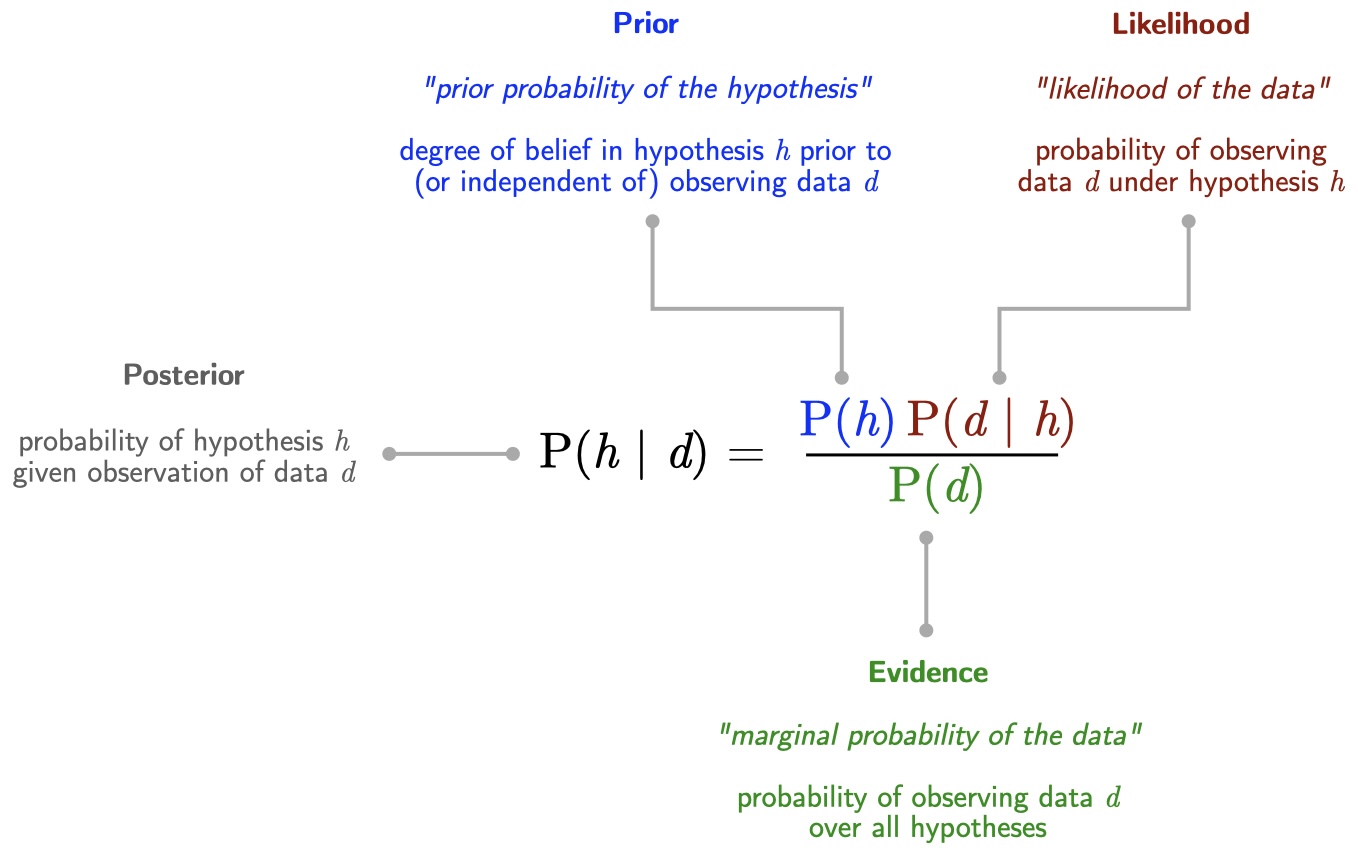
P(h \mid d) = \frac{P(h) \, P(d \mid h)}{P(d)}
This is Bayes’ rule. It follows directly from the definition of conditional probability—it is an algebraic consequence, not an additional assumption.
Why is this useful? Often we want to know the probability of a hypothesis given some observed data, P(h \mid d), but we don’t have direct access to that quantity. What we can typically specify is the likelihood—how probable the data would be under each hypothesis, P(d \mid h)—and the prior probability of each hypothesis, P(h). Bayes’ rule lets us compute the quantity we want from the quantities we have.
There are names for each of the terms.
In the case of this example:
Posterior {P(h \mid d)}: The probability that the coin is biased given that it produced the data d (a sequence of all HEADS). This is what we want to know.
Prior {P(h)}: The probability that the coin is biased before seeing any data. This is 1/10 (since there’s 1 biased coin out of 10).
Likelihood {P(d \mid h)}: The probability of getting all HEADS in 3 flips given that the coin is biased. We’ll calculate this below.
Evidence {P(d)}: The overall probability of getting all HEADS (from either coin). We’ll also calculate this below.
Applying Bayes’ Rule
On paper
Let’s now fill in our probabilities to answer the question.
We know that,
P(h) = \frac{1}{10} = 0.1
since there is 1 biased coin and 9 fair coins.
We also know that for the biased coin,
P(d \mid h) = (0.9)^3 = 0.729
since each flip independently has probability 0.9 of landing HEADS, and we need all three to be HEADS.
NoteAdditional details
More generally, the probability of getting k HEADS in n flips follows a binomial distribution:
P(k \text{ heads in } n \text{ flips}) = \binom{n}{k} \cdot p^k \cdot (1 - p)^{n-k}
In our case, k = n = 3 and p = 0.9, so \binom{3}{3} = 1 and the formula reduces to p^3. For other numbers of heads the binomial coefficient would be non-trivial—e.g., for exactly 2 HEADS in 3 flips, \binom{3}{2} = 3 because there are three distinct sequences (HHT, HTH, THH).
To calculate {P(d)}, we need to consider both the case where the coin is biased and the case where the coin is fair.
The probability that your friend flipped the biased coin is approximately 0.393.
Notice what happened: the prior probability of the biased coin was just 0.1, but after observing three HEADS, the posterior jumped to nearly 0.4—a roughly fourfold increase. The data was diagnostic: getting all HEADS is much more likely under the biased coin (0.729) than the fair coin (0.125), so the observation shifted our belief substantially toward the biased-coin hypothesis. The prior and likelihood together define a generative model—first a coin is drawn (prior), then flips are produced (likelihood)—and Bayes’ rule inverts this generative process to reason from observed data back to probable causes.
In the memo PPL
import jaximport jax.numpy as jnpfrom memo import memofrom memo import domain as productfrom enum import IntEnumclass Coin(IntEnum): TAILS =0 HEADS =1class Bag(IntEnum): FAIR =0 BIASED =1nflips =3S = product(**{f"f{flip+1}": len(Coin) for flip inrange(nflips)})NumHeads = jnp.arange(nflips +1)@jax.jitdef sum_seq(s):return S.f1(s) + S.f2(s) + S.f3(s)@jax.jitdef pmf(s, c):### probability of heads for fair and biased coin p_h = jnp.array([0.5, 0.9])[c]### P(T) and P(H) for coin c p = jnp.array([1- p_h, p_h])### probability of the outcome of each flip p1 = p[S.f1(s)] p2 = p[S.f2(s)] p3 = p[S.f3(s)]### probability of the sequence sreturn p1 * p2 * p3@memodef experiment[_numheads: NumHeads]():### observer's mental model of the process by which### the friend observed the number of heads observer: thinks[### friend draws a coin from the bag friend: draws(c in Bag, wpp=0.1if c == {Bag.BIASED} else0.9),### friend flips the coin 3x friend: given(s in S, wpp=pmf(s, c)),### friend counts the number of HEADS friend: given(numheads in NumHeads, wpp=(numheads==sum_seq(s))) ]### observer learns the number of heads from friend observer: observes [friend.numheads] is _numheads### query the observer: what's the probability that ### the coin c, which your friend flipped, was biased?return observer[Pr[friend.c == {Bag.BIASED}]]xa = experiment(print_table=True, return_aux=True, return_xarray=True).aux.xarraynumheads =3print(f"\n\nP(h=biased | d={numheads}heads) = {xa.loc[numheads].item()}\n")
Imagine that your friend tells you that the coin is red. What is the probability that the sequence of three flips contains exactly 2 Heads?
In this scenario, what is the hypothesis and what is the data?
Describe (in words) the prior, likelihood, evidence and posterior for this scenario, and write out the calculations for each.
Write a memo model to infer the posterior for this scenario.
More data
Suppose your friend draws a coin and flips it 10 times, reporting 9 HEADS. Compute P(\text{biased} \mid 9\text{H in }10) using Bayes’ rule. How does the posterior compare to the 3-flip case? What does this tell you about the relationship between the amount of data and the strength of the posterior update?
The posterior jumps from 0.1 to approximately 0.815—far more dramatic than the 3-flip case (\approx 0.393). With more data, the likelihood ratio becomes more extreme: under the biased coin, 9 heads in 10 is plausible (0.387), but under the fair coin it is very unlikely (0.010). More data allows us to discriminate more sharply between hypotheses.
NoteRender env
%reset -fimport sysimport platformimport importlib.metadataprint("Python:", sys.version)print("Platform:", platform.system(), platform.release())print("Processor:", platform.processor())print("Machine:", platform.machine())print("\nPackages:")for name, version insorted( ((dist.metadata["Name"], dist.version) for dist in importlib.metadata.distributions()), key=lambda x: x[0].lower() # Sort case-insensitively):print(f"{name}=={version}")